
Although Wang was relatively new to producing computers and the 2200 wasn't in the same class as the "big iron" computers, Wang took an admirably long view of how to address its disk drives. Rather than having the CPU microcode directly controlling the disk drive stepper motor and decoding the data, Wang established a protocol that abstracted away the details of the attached disk. This allowed connecting a wide variety of disk drives to the same 2200 CPU without having to rewrite the 2200 microcode for each new drive. The cost was having to put a smart controller on the other end of the cable to translate the abstract protocol into electrical signals that the drive could understand.
In the diagram below, the card labeled "disk interface" is nothing much more than a 2200 I/O bus interface connected to some line drivers and receivers; the disk interface has no intelligence at all. The cable between the 2200 CPU and the disk drive could be tens of feet to hundreds of feet if repeaters were used.
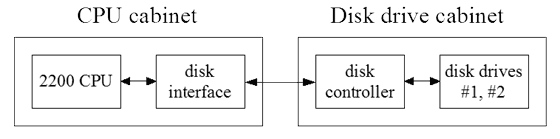
The Wang BASIC disk controller supported only four operations (and only three of them under software control), but eventually with Wang BASIC-2 and higher capacity drives, Wang added more commands to the protocol to increase performance and to address larger drives.
In order to add support for emulated disk drives to WangEmu, the disk channel protocol had to be reverse engineered. Fortunately, one of the Wang internal documents, Module Repair Guide No. 2 is available. Although it doesn't contain a complete description of the protocol, it does have a fairly good description of the microcoded CPU and supplies the microcode listing from the PCS-II disk controller. That listing has been reconstructed as a text document.
The text accompanying the binary microcode is not a complete description of each operation, so a disassembler was written to make all the encoded information explicit. The original listing has been augmented with the disassembled information between "[" and "]" in the enhanced listing. Reverse engineering the details of the protocol became much easier with the enhanced listing.
That was enough to add to the emulator support for the original disk controller protocol. Then another stroke of luck: Paul Szudzik, a principle engineer of Southern Data Systems, supplied one of SDS's internal documents of their reverse engineering of the disk channel protocol for both the original and the later, intelligent disk controller.
First, a few general properties of the Wang disk model:
- all sectors contain 256 bytes, from the smallest floppy disk to the largest hard disk
- sectors are logically addressed sequentially starting from 0; it is up to the disk controller to map the sequential sector address to a track and sector-of-track address
- the disk controller is responsible for performing any sector interleave computation
- a disk may have at most 65536 sectors because sector addresses are communicated via a 16 bit number; this puts a limit on a logical disk size of 16 MB. Physically larger disks would have to be partitioned into smaller logical disks, each of which is 16 MB or less. In 1973 that probably seemed reasonable, but before 1980 Wang was already hitting that limitation.
- in the original dumb disk controller, a disk surface could have at most 32K sectors
- in the original dumb disk controller, the fact that the disk pack might have more than one platter was transparent to the host CPU -- the controller would map the up to 32K sectors onto the appropriate platter
- the intelligent controller allowed the CPU to address multiple platters of a disk explicitly, which was necessary as a single platter could hold up to 64K sectors
- the communication protocol has a lot of error checking. All command bytes sent from the 2200 CPU to the disk controller get echoed back from the controller to the CPU; if the echoed byte is incorrect, the 2200 can abort the operation before any changes are made to the disk. All data transfers have an LRC byte appended. All operations have one or more points where the disk controller can signal to the 2200 CPU that an error has been detected.
- the protocol doesn't allow for queuing commands at the disk controller (although it might be done at the 2200 CPU side, it wasn't useful to do so until the MVP evolution), nor does it allow seeking to a given track other than by reading a sector on that track.
- a disk channel is attached to at most two drives: drive #1 and drive #2
- data on the disk is protected by a 16 bit CRC checksum, and data transferred across the disk channel is protected by an LRC checksum byte (sum of all 256 bytes mod 256). The CRC generation and checking is hidden from the 2200 other than the fact that a status byte returned from the disk controller can indicate that the sector had a CRC checksum error.
There are four operations supported by the first generation (dumb) disk controller:
- format a disk (not software controllable; triggered via a button)
- read a sector
- write a sector
- verify a sector
Format a Disk (hardware controlled) (link)
Disks are formatted by pressing a recessed button on the front of the disk unit housing. Any disk in drive #1 will be formatted and verified. While this is going on, an LED blinks on the front panel to let the operator know that the format is in progress. Although it seems inconvenient that the format function isn't accessible from software, it guarantees that an errant program can't accidentally format the disk.
Part of formatting includes writing a header indicating the track and sector address of each sector and writing a zeroed out data payload and LRC byte.
Command Initiation (dumb controllers) (link)
The first question is: how does the CPU know if the disk controller can handle the newer commands? The protocol will be detailed below, but the first step is the host CPU sends a "wake up" command to the controller, and the controller replies with a response byte. The dumb controllers response byte is 0xC0, while the intelligent controllers respond with 0xD0.
The three commands that a dumb controller can handle (read, write, verify) begin with a common handshake sequence that will be detailed here so it doesn't need to be repeated for each command description later.
In the sequences listed below, some transfers from the Wang have a (*) after the byte listed, and the comment sometimes mentions "CAX." In the Wang I/O bus protocol, the CPU puts the address of the device it wants to communicate with on the address bus (AB), then it sends an address strobe (ABS) to finally select the device. That selection is maintained until the next ABS strobe. After the ABS strobe, the AB bus can be set to an arbitrary 8 bit value without affecting the selection. Most devices don't use AB other than during the selection phase, but the disk controller is different. It monitors the AB bus during output data strobes (OBS) to signal whether the 2200 CPU wants to continue the sequence or if it wants to abort and restart. Specifically, if bits 8 and 6 of AB are 1, it indicates that the sequence in progress is to be aborted. In fact, the disk controller doesn't always monitor CAX and only checks it at certain junctures in the sequence.
Table 1 shows the first few transfers of this handshake that is common to the read, write, and verify commands. If the status byte returned by the disk controller in step 9 is not 0x00, then the 2200 CPU and the disk controller stop the sequence in progress and the 2200 must start a new command sequence by sending the CAX reinit request from step 1.
The three command bytes sent from the 2200 to the disk controller are the operation and drive selection byte, the most significant 8 bits of the sector address, then the least significant 8 bits of the sector address. As each of these three command bytes are received, the CAX condition is checked and if true, the disk controller aborts the sequence and replies with 0xC0 and continues on with step 3 of the command initiation sequence. This is used, for example, if the 2200 sends a command byte that either the disk controller receives incorrectly or the echo is received by the 2200 incorrectly; not trusting what the disk controller might have received, the 2200 CPU just aborts the command altogether.
Error responses are produced at other junctures of the sequences, and not just step 9. The status bytes that appear to be in use are given in Table 2, below.
| step | 2200 sends | disk sends | comment |
|---|---|---|---|
| 1 | 0x00* | CAX re-init request | |
| 2 | 0xC0 | re-init request acknowledgment, indicating dumb controller | |
| 3 | <command byte 1> | read/write/verify command (cmd1) 0x00: read sector, drive #1 0x10: read sector, drive #2 0x40: write sector, drive #1 0x50: write sector, drive #2 0x80: verify sector, drive #1 0x90: verify sector, drive #2 |
|
| 4 | <command byte 1> | echo cmd1 | |
| 5 | msaddr | ms sector address (cmd2) | |
| 6 | msaddr | echo cmd2 | |
| 7 | lsaddr | ls sector address (cmd3) | |
| 8 | lsaddr | echo cmd3 | |
| 9 | <status> | 0x00 means OK, otherwise an error has occurred | |
| ... rest of sequence | |||
| status byte | meaning |
|---|---|
| 0x00 | OK |
| 0x01 | illegal sector address, or missing media, or miscompare, or write data LRC error |
| 0x02 | sector error |
| 0x04 | CRC error |
| 0x80 | compare |
| 0xC0 | reinit response |
Read a Sector (link)
| step | 2200 sends | disk sends | comment |
|---|---|---|---|
| 1 | 0x00* | CAX re-init request | |
| 2 | 0xC0 | re-init request acknowledgment | |
| 3 | 0x00 | read command (cmd1) | |
| 4 | 0x00 | echo cmd1 | |
| 5 | msaddr | ms sector address (cmd2) | |
| 6 | msaddr | echo cmd2 | |
| 7 | lsaddr | ls sector address (cmd3) | |
| 8 | lsaddr | echo cmd3 | |
| At this point the disk controller checks the legality of the sector address, starts up the motor if it isn't already running, checks that there is a disk in the drive, steps the head to the desired track, then keeps reading sectors from the track until the one matching the desired sector is encountered. | |||
| 9 | <status> | 0x00 means OK, otherwise an error has occurred | |
| 10 | 0x00 (*) | data ignored; abort to step 2 if CAX | |
| 11 | <status> | status byte 0x00: OK 0x02: sector error 0x04: CRC error |
|
| 12 | data[0] | first byte of sector | |
| 13 | data[1] | second byte of sector | |
| ... | ... | ||
| 14 | data[255] | last byte of sector | |
| 15 | LRC | checksum | |
Write a Sector (link)
| step | 2200 sends | disk sends | comment |
|---|---|---|---|
| 1 | 0x00* | CAX re-init request | |
| 2 | 0xC0 | re-init request acknowledgment | |
| 3 | 0x40 | write command (cmd1) | |
| 4 | 0x40 | echo cmd1 | |
| 5 | msaddr | ms sector address (cmd2) | |
| 6 | msaddr | echo cmd2 | |
| 7 | lsaddr | ls sector address (cmd3) | |
| 8 | lsaddr | echo cmd3 | |
| The disk controller verifies the sector address; spins up the disk; checks that a disk is in the drive; steps to the appropriate track | |||
| 9 | <status> | 0x00 means OK, otherwise an error has occurred | |
| 10 | data[0](*) | first byte of sector; abort to step 2 if CAX | |
| 11 | data[1](*) | second byte of sector; abort to step 2 if CAX | |
| ... | ... | ||
| 12 | data[255](*) | last byte of sector; abort to step 2 if CAX | |
| 13 | LRC | checksum | |
| time passes -- the sector is written to the disk | |||
| 14 | <status> | final status; 0x00 if completed successfully; not 0x00 if LRC or other error | |
Verify a Sector (link)
Verify sector is a hybrid of read and write. The beginning of the sequence is identical to the read sector sequence; in fact, the microcode has a common path for verify and the read sector routines. Once the sector has been read successfully, the 2200 CPU sends the data it is expecting. The disk controller verifies each byte against what was just read off the disk and if after the 256 data bytes and LRC checksum byte have been received, if any of the 256 data bytes mismatch what was on the disk, an error code of 0x01 is returned, otherwise it's 0x00.
| step | 2200 sends | disk sends | comment |
|---|---|---|---|
| 1 | 0x00* | CAX re-init request | |
| 2 | 0xC0 | re-init request acknowledgment | |
| 3 | 0x80 | verify command (cmd1) | |
| 4 | 0x80 | echo cmd1 | |
| 5 | msaddr | ms sector address (cmd2) | |
| 6 | msaddr | echo cmd2 | |
| 7 | lsaddr | ls sector address (cmd3) | |
| 8 | lsaddr | echo cmd3 | |
| spin up disk, step to appropriate track | |||
| 9 | <status> | 0x00 if OK, otherwise an error has occurred | |
| 10 | 0x00 (*) | data ignored; abort to step 2 if CAX | |
| time passes -- the sector is read from the disk | |||
| 11 | <status> | status byte 0x00: OK 0x02: sector error 0x04: CRC error |
|
| 12 | data[0] | first byte of sector | |
| 13 | data[1] | second byte of sector | |
| ... | ... | ||
| 14 | data[255] | last byte of sector | |
| 15 | LRC | checksum, but ignored by disk controller | |
| 16 | <status> | final status; 0x00 if OK, 0x01 if mismatch | |
Wang LVP Disk Command Sequences (link)
Years after writing the document above and below this section, an internal Wang document was given to me by a former Wang engineer. It describes the disk command sequences used by the 2200 LVP system. It restates much of what was given above, but also documents advanced commands used by the intelligent disk controllers.
SDS Disk Channel Description (link)
Below is an HTML-ized version of an internal document generated by Paul Szudzik for Southern Data Systems (SDS), circa 1986, which describes the disk protocol for both the first generation and the smarter second generation of disk controllers, which supported more commands.
The intelligent disk controllers added new commands to the protocol to allow for addressing larger drives, and for operating on a group of consecutive sectors for greater throughput. The commands added by the 2nd generation disk controllers were:
- copy sectors
- format disk (software controlled)
- start multi-sector write
- end multi-sector write
- verify a range of sectors
Command Structure (link)
The process of sending commands to the disk controller from the 2200 system is divided up into the following structure:
- Wakeup phase
- The controller is informed that some communication is to take place and identifies which of the two possible disks attached will be addressed.
- First Status
- Controller informs the 2200 whether further communication is possible, and if so, whether it is intelligent or dumb.
- Command
- The command, as well as the platter selection bits are passed to the controller.
- Sector
- A three byte sector address is transferred.
- Second Status
- Report back to the 2200 whether the indicated platter/disk is available, or whether the sector address specified is valid.
- Execution
- The command is normally executed at this point, with reception or transmission of data taking place.
- Final Status
- The result of the operation is passed back to the 2200 system.
Wakeup Phase (link)
The start of a sequence is normally began by the 2200 selecting the disk controller. The selection sequence also includes the address of the disk unit to be addressed as well. The following information is passed on the Address Bus in conjunction with the ABS strobe.
0 D X X 0 0 0 0
Where X X stands for the address of the controller to be addressed.
Where D stands for the disk drive to be addressed. 0 is the primary drive, while 1 indicates the secondary drive. The lower part of the address bus must be all zeroes for any intelligent disk. After the selection process has taken place, the 2200 will monitor the state of the Ready-Busy bit from the controller.
If in a Ready state the 2200 will place the value hex A0 on the Address Bus and send data to the controller via an OBS strobe. The data sent to the controller is as follows:
| Data | Meaning |
|---|---|
| 00 | Model 'T' machine is trying to communicate or in PROM mode on the 2200 system. Data transmissions should be in slow mode. |
| 01 | 2200 VP machine is communicating. Data transmissions are to be done in Fast mode. |
| 02 | 2200 MVP processor is communicating. Data transmissions are to be done in Fast mode. |
First Status (link)
After the initial wakeup byte has been transferred, the controller must inform the 2200 as to whether it is capable of receiving further commands, or aborting this sequence.
If capable, the controller will send either the value hex C0 if the controller is dumb, or hex D0 if intelligent. If not capable, the value 01 should be sent. The 2200 will store the response and act accordingly.
If the controller responds with an 01 code, an 190 error will be reported to the calling program in the 2200. This code should be sent to the 2200 only if the controller is not operational, i.e., it has bad ram, fails diagnostics, or otherwise sick.
After reception of the type of controller, the 2200 will change the address bus to hex 40, but no further ABS will be generated. This will inform the controller that command information will follow. The 2200 will then place the command to be executed on the data bus and issue an OBS strobe. The structure of the command is as follows:
C C C R H H H H
Where HHHH is the head to be addressed.
Where R equals fixed or removable media.
Where CCC is the actual command as deciphered below:
| CCC | Meaning |
|---|---|
| 000 | Read command |
| 010 | Write command |
| 100 | Read after Write command |
| 001 | Special Command. If the special command is executed, another byte of data will be sent, specifying what special command is to be executed. The special commands will be discussed later in this document. |
The controller will respond to the command by echoing back the data to the 2200 system.
Sector Data (link)
Following a normal command, the 2200 will send several bytes of data to the controller which are the sector address to be acted upon. This will only occur for a normal command. Special commands are handled differently. The number of bytes transferred will vary depending upon how the controller responded to the Wakeup phase. If the controller responded as a dumb disk, only two bytes will be transferred, and the value of the two bytes can not exceed 32768 sectors. An intelligent disk will receive three bytes, with a current limit of 65536 sectors that can be addressed. In this mode, the first byte is always zero.
Each byte received must be echoed by the controller. This is a check by the 2200 to ensure that the data is being received correctly. If the 2200 receives wrong data back, it will simply retry the entire sequence again.
At the end of the reception of the sector data, the controller should immediately drop its Ready status, and determine whether it can execute the command.
Second Status (link)
Status must be sent back to the controller after the reception of the sector data, informing the 2200 as to whether it can proceed with the command. The following statuses can be sent back:
| Data | Meaning |
|---|---|
| 00 | No problems, everything is good |
| 01 | Error I98. Report this back to the 2200 if the sector address passed to the controller exceeds the maximum legal sector address of the platter. For a read operation, all sectors, including the remapped sectors are legal. For normal write operations, sectors up to but not in the remap sector are valid. As an example, sector 52608 on a FSD is the start of the remap area for defective sectors. This sector may be read, but cannot be written to with the normal write command. |
| 02 | Error I91. Report this back to the 2200 if the selected disk drive is not in the Ready state, or if the selection of the head is incorrect. |
| 01 | Error I94. This is a vestige from the 10 meg disk days, and is used to inform the 2200 that the FORMAT KEY is still engaged. |
Any error condition that occurs here should send the controllers program back to the idle, monitor state. Only a 00 status will allow the controller to proceed.
Execution Phase - Write Command (link)
After transmission of the last status byte, the 2200 will send over 256 bytes of data to be written at the requested sector, with a 257th checksum byte. If the checksum byte is incorrect, indicating a problem with the transmission, the controller must send back an 04 status byte.
With the data received, the controller must drop Ready status. A check is made to see if the controller is in a Multi-Sector Mode of operation. If it is, the data just received may or may not be written to the disk at this time. If is not in Multi-Sector mode, the write operation is performed.
Upon finishing, a single status byte is always sent back, even though the sector may not have been written onto the disk because of Multi-Sector mode. The structure of the status bytes is as follows:
| Data | Meaning |
|---|---|
| 00 | No problems encountered. |
| 01 | Error I95. The requested unit is write protected. |
| 02 | Error I93. An error occurred while writing. This is a catch all error and could indicate a seek error, a header error, or a timing problem of some type. |
Execution Phase - Read After Write (link)
After reception of the 00 byte, Ready should be immediately dropped. The controller will attempt to read the requested sector, performing all retries transparent to the host 2200 system. At the completion of the read, status will be sent back to the controller. This status byte may be the following:
| Data | Meaning |
|---|---|
| 00 | Data read successfully |
| 01 | Error I95. Seek error occurred, command aborted. |
| 02 | Error I93. Header was defective on the selected sector. |
| 04 | Error I96. Data had a ECC or CRC error and could not be corrected. |
If status was not 00, the 2200 will report an 199 error to the program and abort the operation. If status was good, the host 2200 will send 256 bytes of data to the controller, followed by the checksum of data. The controller will send back an 04 status byte if the checksum does not match the internally computed checksum.
Data received is compared against the read buffer, which could occur at the same time as the data from the 2200 is being received. If data compares, a 00 status is sent back. Else a status of 01 is sent back.
Abnormal Termination of Commands (link)
In most cases, the 2200 would be the originator of the abort commands. The primary reason for the abort command would be the depression of the RESET key on the terminal during a disk operation.
An abort operation is defined as bit 1 of the data bus being active and the production of a CBS code. This produces a reset signal, decoded by hardware in the controller, to the disk program. This reset should cause the controller to clean up any stray signals left over, and resume polling for another command. Issuing the reset command in the middle of a sequence, such as a write command, may leave the disk in a corrupt condition.
A second type of abort command may occur if a mis-communication takes place between the 2200 and the disk controller. A signal called REINIT will be produced by placing the value of hex A0 on the Address bus and pulsing the OBS signal. Normally, this REINIT configuration is detected by software status. This is a clean type of reset, where the controller is normally in a known state.
The last type of abort is produced by the controller itself upon detection of an abnormal condition. An example of this would be a seek error. The normal command is aborted, and a status byte is attempted to be sent back to the processor.
Special Commands (link)
Special commands allow operations to occur that in most cases are outside of the normal functions of the operating system. The special commands have been identified as having the 20 bit set in the command byte. Once this byte has been echoed by the controller, the 2200 will send a Special command modifier byte, which must also be echoed, that will indicate the operation to be performed.
A list of the special command modifier bytes supported by the Wang operating system are as follows:
| Data | Meaning |
|---|---|
| 01 | Copy sectors |
| 02 | Format Disk |
| 10 | Start of Multi-sector Write operation |
| 11 | End Multi-sector write operation |
| 12 | Verify a range of sectors |
| 15 | Read sector and hang |
| 16 | Read status and Prom Revisions |
A secondary list of special command modifiers has been defined by SDS. The list of 2290-DPU modifiers are as follows:
| Data | Meaning |
|---|---|
| F0 | Dump arena |
| F2 | Send disk status |
| F5 | Change head configuration |
| F7 | Unprotected Write sector |
| F8 | Add sector to Remap track |
| F9 | Change drive configuration table |
| FB | Long format |
| FC | Singular Sector Format |
| FD | Fast format |
Unfortunately, I don't have the complete document, so extended commands 15, 16, and F0-FD are a mystery.
One might wonder why there are commands for performing a multi-sector write operation, but no multi-read sector operation. I believe the reason is that the smart disk controller did track and sector caching. For instance, if the host CPU requested sector 100, the controller would seek to the appropriate track and start decoding sectors. Rather than just waiting for the requested sector and reading only that sector, the controller would read and buffer all sectors that appeared beneath the read head. After reading sector 100, the CPU would very likely request to read sector 101, and the controller would have already speculatively read it, so with low latency it could deliver the read data from its cache buffer. Such a scheme works for reads, but not writes, because reads are non-destructive.
Copy Sequence (link)
The copy sequence is used to transfer a range of sector data from one area of a disk, to either another area of the same disk, or to another disk unit. Once this byte has been received, three bytes of sector information are received, as in section 2.4.
The received sector information is the start of the area to be copied. The controller must ascertain if this is a valid sector address, and returns status as follows:
| Data | Meaning |
|---|---|
| 00 | No problems, everything is good |
| 01 | Error I98. Report this back to the 2200 if the sector address passed to the controller exceeds the maximum legal sector address of the platter. |
| 02 | Error I91. Report this back to the 2200 if the selected disk drive is not in the Ready state, or if the selection of the head is incorrect. |
If a status of 00 is sent, the 2200 will send three more sector bytes to the controller as in section 2.4. These bytes represent the ending sector address to be copied. The controller verifies that the sector is valid, and will return the following statuses:
| Data | Meaning |
|---|---|
| 00 | No problems, everything is good |
| 01 | Error I98. Report this back to the 2200 if the sector address passed to the controller exceeds the maximum legal sector address of the platter. |
| 02 | Error I91. Report this back to the 2200 if the selected disk drive is not in the Ready state, or if the selection of the head is not correct. |
The 2200 will now readdress the controller, placing the destination disk bit onto the Address bus. A Read command is received by the controller, containing information about the destination drive, the format of this read command is the same as in section 2.3.
After the read command is transmitted, three more byte; of sector data will be transferred as in section 2.4. These bytes represent the starting sector address of the destination area to be copied to. Since no ending sector need to be sent, the program must compute the number of sectors to be transferred from the copy from parameters, and ensure that they can be fit onto the destination.
At this time, the controller should report back status to indicate that the second disk selection was valid. The returned status should appear as
| Data | Meaning | |
|---|---|---|
| 00 | No problems, everything is good | |
| 01 | Error I98. Report this back to the 2200 if the sector address passed to the controller exceeds the maximum legal sector address of the platter | |
| 02 | Error I91. Report this back to the 2200 if the selected disk drive is not in the Ready state, or if the selection of the head is not correct. |
If status of 00 was sent, the 2200 will then send a 00 byte to the controller, to indicate that the controller should start the operation. The controller must drop the Ready state till the operation is completed.
At the end of the operation, status is sent back to the controller as follows:
| Data | Meaning |
|---|---|
| 00 | No problems encountered. |
| 01 | Error I95. The requested unit is write protected. |
| 01 | Error I93. An error occurred while writing. This is a catch all error and could indicate a seek error, a header error, or a timing problem of some type. |
Format Disk Sequence (link)
The format disk command will cause the controller to Reformat and certify the selected disk and platter. Bad sectors will be detected and remapped during this operation. After receiving the modifier byte, the 2200 will send a 00 byte to the controller. The controller will drop ready and perform the format. At the completion of the format operation, the controller sends the following status back to the 2200:
| Data | Meaning |
|---|---|
| 01 | No problems encountered. |
| 01 | Error I95. The requested unit is write protected. |
| 02 | Error I93. An error occurred while formatting. This is a catch all error and could indicate a seek error, a header error, or a timing problem of some type. This could also mean that enough sectors were bad that the remap track overflowed. The disk would be in an unreadable state. |
Start of Multi-Sector Write Mode (link)
After the receipt of the modifier byte, a 00 byte will be sent from the 2200 to the controller to enter this mode of operation. No response from the controller should be given.
This command may be sent by the 2200 system to inform the controller that multiple sectors are to be transferred to the controller to be written on the disk. The controller would store the sectors received on subsequent write commands without writing them to the disk to achieve a faster throughput rate.
The controller would write the sectors when a natural boundary would be crossed, such as index, write cache filled, or another command, other than a write command was received. Furthermore, if a command is received while in this mode that is targeted to another drive or head than that set by the Multi-Sector mode, the cache is dumped. The latter scenario can only occur if this mode is entered via $GIO command, and could result in confusing status data to be reported back to the command issued if an error occurs during the write of the cache.
End of Multi-Sector Write Mode (link)
This sequence will specify that no further write commands are to be issued within the Multi-sector sequence. It informs the controller to dump any sectors that have not been written yet.
After the modifier byte has been received, a 00 byte from the 2200 will be received. No echo of this byte should be done. When this byte has been received, Ready should be dropped, and the sectors written. After all sectors have been written, status should be sent back as follows:
| Data | Meaning |
|---|---|
| 00 | No problems encountered. |
| 01 | Error I95. The requested unit is write protected. |
| 02 | Error I93. An error occurred while writing. This is a catch all error and could indicate a seek error, a header error, or a timing problem of some type. |
Verify Sequence (link)
The verify sequence scans the disk over a specified range of sectors and reports back status of the sectors. At the first error that occurs, the command is aborted, and the sector address that failed is sent back to the 2200 system.
After reception of the modifier byte, the 2200 will send three bytes of sector information per section 2.4. These three bytes will be the starting sector to perform the verification on. After receiving the sector data, status is reported back as follows:
| Data | Meaning |
|---|---|
| 00 | No problems, everything is good |
| 01 | Error I98. Report this back to the 2200 if the sector address passed to the controller exceeds the maximum legal sector address of the platter. |
| 02 | Error I91. Report this back to the 2200 if the selected disk drive is not in the Ready state, or if the selection of the head is incorrect. |
Wang will now send three more bytes of sector data as per section 2.4. This sector data refers to the ending sector to be verified. Again, we confirm that the sectors requested are within our limits, and send back another status byte as follows:
| Data | Meaning |
|---|---|
| 00 | No problems, everything is good |
| 01 | Error I98. Report this back to the 2200 if the sector address passed to the controller exceeds the maximum legal sector address of the platter. |
| 02 | Error I91. Report this back to the 2200 if the selected disk drive is not in the Ready state, or if the selection of the head is incorrect. |
If a 00 status byte was sent, the 2200 will now send a 00 byte to the controller. This will indicate that the verification operation should proceed. The 00 byte is not echoed, but the Ready bit should be dropped immediately. The verification sequence is then executed.
If no errors are detected during the verify, three bytes of 00 are sent to the 2200 system, and the command is terminated.
If an error is detected, two bytes, representing the sector in error are sent to the 2200. A third byte is sent depicting what the reason for the abort was. This byte is defined as:
| Data | Meaning |
|---|---|
| 01 | Seek error occurred, command aborted. |
| 02 | Header was defective on the selected sector. |
| 04 (?) | Data had a ECC or CRC error and could not be corrected. |